

声明:本文是转载的,只收集了30余种加密编码类型,关于他们的介绍来源于网络,重点讲的是他们的密文特征,还有很多类型没有讲到,后续等我研究明白了再发,转载请注明来源(原文),感谢支持
全能型加密识别:https://www.dcode.fr/cipher-identifier
自动识别工具:https://github.com/Ciphey/Ciphey
一、MD5、sha1、HMAC算法、NTLM等相似加密类型
hash-identifier
hash-identifier就是一款由python编写,可以快速识别hash加密类型的工具
执行命令启动程序
hash-identifier
输入哈希密文
hash-identifier 它会列出最有可能的两种加密算法:Possible Hashs:和可能性不大的Least Possible Hashs:
hashid
可识别大约210种HASH算法:给他个hash值,他就能判断出这个值是哪种类型的hash值
hashid -h
usage: hashid.py [-h] [-e] [-m] [-j] [-o FILE] [--version] INPUT
-e,--extended 列出所有可能的散列算法,包括加密密码
-m,--mode 在输出中包括相应的hashcat模式
-j,--john 在输出中包括相应的JohnTheRipper格式
-o FILE,--outfile FILE 将输出写入文件(默认值:STDOUT)
-h,--help 显示帮助信息并退出
--version 显示程序的版本信息并退出
1、MD5——示例21232F297A57A5A743894A0E4A801FC3
一般MD5值是32位由数字“0-9”和字母“a-f”所组成的字符串,如图。如果出现这个范围以外的字符说明这可能是个错误的md5值,就没必要再拿去解密了。16位值是取的是8~24位。

md5的三个特征:
确定性:一个原始数据的MD5值是唯一的,同一个原始数据不可能会计算出多个不同的MD5值。
碰撞性:原始数据与其MD5值并不是一一对应的,有可能多个原始数据计算出来的MD5值是一样的,这就是碰撞。
不可逆:也就是说如果告诉你一个MD5值,你是无法通过它还原出它的原始数据的,这不是你的技术不够牛,这是由它的算法所决定的。因为根据第4点,一个给定的MD5值是可能对应多个原始数据的,并且理论上讲是可以对应无限多个原始数据,所有无法确定到底是由哪个原始数据产生的。
MD5加密解密命令
echo -n "123" | md5sun国内Md5解密:
http://t007.cn/
https://cmd5.la/
https://cmd5.com/ 【推荐】
https://pmd5.com/
http://ttmd5.com/
https://md5.navisec.it/
http://md5.tellyou.top/
https://www.somd5.com/ 【推荐】
http://www.chamd5.org/国外Md5解密:
https://www.md5tr.com/
http://md5.my-addr.com/
https://md5.gromweb.com/
https://www.md5decrypt.org/
https://md5decrypt.net/en/
https://md5hashing.net/hash/md5/
https://hashes.com/en/decrypt/hash
https://www.whatsmyip.org/hash-lookup/
https://www.md5online.org/md5-decrypt.html
https://md5-passwort.de/md5-passwort-suchenMySQL破解:
https://www.mysql-password.com/hash2、sha1——示例:d033e22ae348aeb5660fc2140aec35850c4da997
这种加密的密文特征跟MD5差不多,只不过位数是40

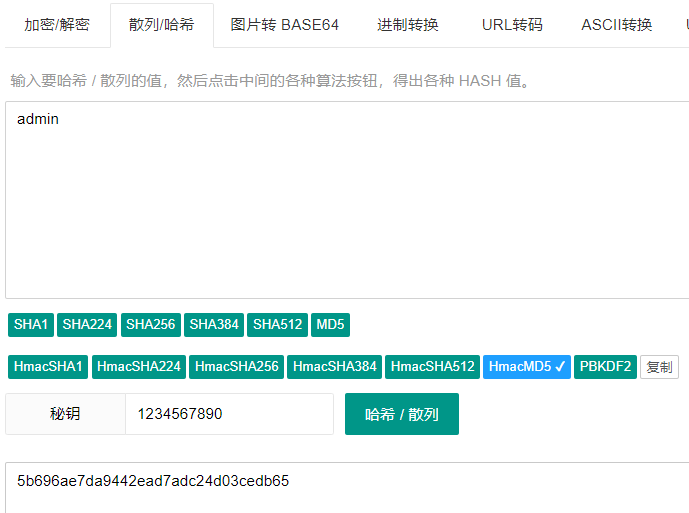
3、HMAC算法——示例:5b696ae7da9442ead7adc24d03cedb65
HMAC (Hash-based Message Authentication Code) 常用于接口签名验证,这种算法就是在前两种加密的基础上引入了秘钥,而秘钥又只有传输双方才知道,所以基本上是破解不了的
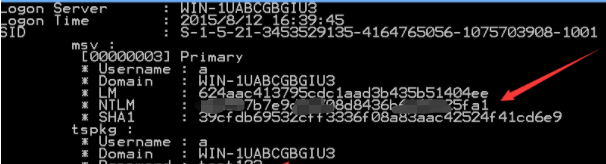
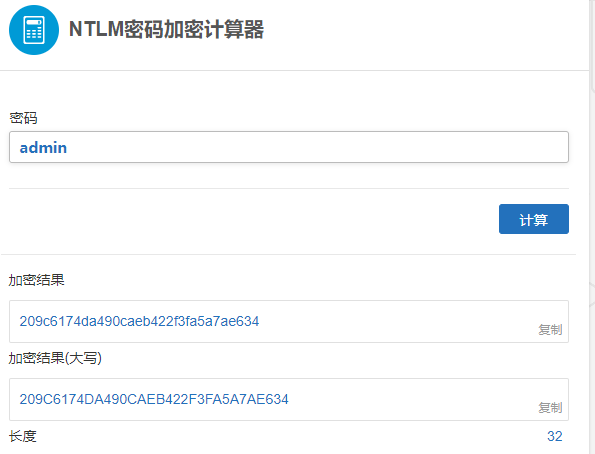
3、NTLM——示例:209c6174da490caeb422f3fa5a7ae634
这种加密是Windows的哈希密码,是 Windows NT 早期版本的标准安全协议。与它相同的还有Domain Cached Credentials(域哈希)。
相似加密类型
|序号|算法|长度|
|—|—|—|
|1|md5|32/16|
|2|sha1|40|
|3|sha256|64|
|4|sha512|128|
|5|adler32|8|
|6|crc32|8|
|7|crc32b|8|
|8|fnv132|8|
|9|fnv164|16|
|10|fnv1a32|8|
|11|fnv1a64|16|
|12|gost|64|
|13|gost-crypto|64|
|14|haval128,3|32|
|15|haval128,4|32|
|16|haval128,5|32|
|17|haval160,3|40|
|18|haval160,4|40|
|19|haval160,5|40|
|20|haval192,3|48|
|21|haval192,4|48|
|22|haval192,5|48|
|23|haval224,3|56|
|24|haval224,4|56|
|25|haval224,5|56|
|26|haval256,3|64|
|27|haval256,4|64|
|28|haval256,5|64|
|29|joaat|8|
|30|md2|32|
|31|md4|32|
|32|ripemd128|32|
|33|ripemd160|40|
|34|ripemd256|64|
|35|ripemd320|80|
|36|sha224|56|
|37|sha3-224|56|
|38|sha3-256|64|
|39|sha3-384|96|
|40|sha3-512|128|
|41|sha384|96|
|42|sha512/224|56|
|43|sha512/256|64|
|44|snefru|64|
|45|snefru256|64|
|46|tiger128,3|32|
|47|tiger128,4|32|
|48|tiger160,3|40|
|49|tiger160,4|40|
|50|tiger192,3|48|
|51|tiger192,4|48|
|52|whirlpool|128|
|53|mysql|老MYSQL数据库用的,16位,且第1位和第7位必须为0-8|
|54|mysql5|40|
|55|NTLM|32|
|56|Domain Cached Credentials|32|
|常用解密网站:|||
二、Base64、Base58、Base32、Base16、Base85、Base100等相似加密类型
1、Base64——示例YWRtaW4tcm9vdA==
一般情况下密文尾部都会有两个等号,明文很少的时候则没有
Base64编码要求把3个8位字节(38=24)转化为4个6位的字节(46=24),之后在6位的前面补两个0,形成8位一个字节的形式。 如果剩下的字符不足3个字节,则用0填充,输出字符使用‘=’,因此编码后输出的文本末尾可能会出现1或2个‘=’,如图:

为了保证所输出的编码位可读字符,Base64制定了一个编码表,以便进行统一转换。编码表的大小为2^6=64,这也是Base64名称的由来。
Base64编码表
|码值|字符|码值|字符|码值|字符|码值|字符|码值|字符|码值|字符|码值|字符|码值|字符|
|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|
|0|A|8|I|16|Q|24|Y|32|g|40|o|48|w|56|4|
|1|B|9|J|17|R|25|Z|33|h|41|p|49|x|57|5|
|2|C|10|K|18|S|26|a|34|i|42|q|50|y|58|6|
|3|D|11|L|19|T|27|b|35|j|43|r|51|z|59|7|
|4|E|12|M|20|U|28|c|36|k|44|s|52|0|60|8|
|5|F|13|N|21|V|29|d|37|l|45|t|53|1|61|9|
|6|G|14|O|22|W|30|e|38|m|46|u|54|2|62|+|
|7|H|15|P|23|X|31|f|39|n|47|v|55|3|63|/|
Base64使用注意问题
一、Base64和URL传参问题
标准的Base64并不适合直接放在URL里传输,因为URL编码器会把标准Base64中的“/”和“+”字符变为形如“%XX”的形式,而这些“%”号在存入数据库时还需要再进行转换,因为ANSI SQL中已将“%”号用作通配符。
为解决此问题,可采用一种用于URL的改进Base64编码,它在末尾填充’='号,并将标准Base64中的“+”和“/”分别改成了“-”和“_”,这样就免去了在URL编解码和数据库存储时所要作的转换,避免了编码信息长度在此过程中的增加,并统一了数据库、表单等处对象标识符的格式。
二、Base64和URL传参问题改善
另有一种用于正则表达式的改进Base64变种,它将“+”和“/”改成了“!”和“-”,因为“+”,“*”以及前面在IRCu中用到的“[”和“]”在正则表达式中都可能具有特殊含义。
此外还有一些变种,它们将“+/”改为“-”或“.”(用作编程语言中的标识符名称)或“.-”(用于XML中的Nmtoken)甚至“_:”(用于XML中的Name)。
三、Base64转换后比原有的字符串长1/3
Base64要求把每三个8Bit的字节转换为四个6Bit的字节(38 = 46 = 24),然后把6Bit再添两位高位0,组成四个8Bit的字节,也就是说,转换后的字符串理论上将要比原来的长1/3。
四、Base64转换总结
Base64转换,最好是不要用在加密上,尤其是参数加密,很容易出问题。
base64加密解密命令
echo 123 | base64 -i
echo 123 | base64 -d
base64解码python脚本
import base64
g = open('s-out.txt','a+')
with open('s.txt','r') as f:
for line in f.readlines():
word = base64.b64decode(line.strip())
g.write(word.decode('utf-8')+'\n')
g.close()
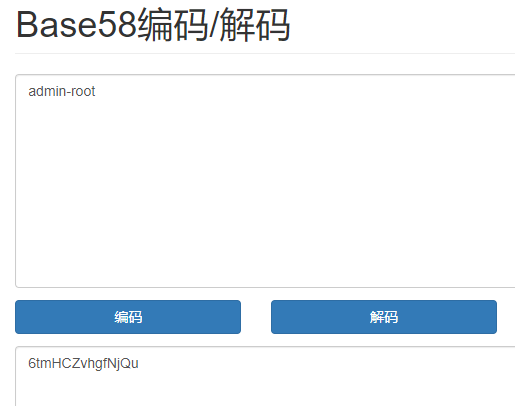
2、Base58——示例6tmHCZvhgfNjQu
它最大的特点是没有等号
Base58是用于比特币(Bitcoin)中使用的一种独特的编码方式,主要用于产生Bitcoin的钱包地址。
相比Base64,Base58不使用数字"0”,字母大写"O”,字母大写"I”,和字母小写"l”,以及”+“和”/“符号。
比特币的Base58字母表:
123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz
简单的说:Base58一种编码方式,跟十进制,十六进制一样,不过更短更省空间。
Base58的原理是什么?
二进制:0和1
十进制:1到10
十六进制:十进制的基础上加上了A-F 六个字母
Base58可以理解为一种58进制。
Base58包含了阿拉伯数字、小写英文字母,大写英文字母。
但是去掉了一些容易混淆的数字和字母:0(数字0)、O(o的大写字母)、l( L的小写字母)、I(i的大写字母)
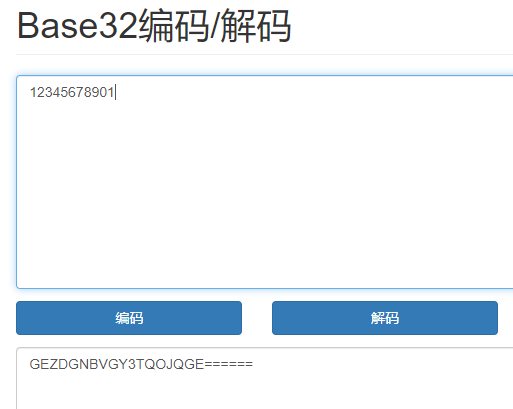
3、Base32——示例GEZDGNBVGY3TQOJQGE======
他的特点是明文超过十个后面就会有很多等号
Base32使用了ASCII编码中可打印的32个字符(大写字母AZ和数字27)对任意字节数据进行编码.Base32将串起来的二进制数据按照5个二进制位分为一组,由于传输数据的单位是字节(即8个二进制位).所以分割之前的二进制位数是40的倍数(40是5和8的最小公倍数).如果不足40位,则在编码后数据补充”=“,一个”=“相当于一个组(5个二进制位),编码后的数据是原先的8/5倍. Base32编码表
|值|符号|值|符号|值|符号|值|符号|
|—|—|—|—|—|—|—|—|
|0|A|8|I|16|Q|24|Y|
|1|B|9|J|17|R|25|Z|
|2|C|10|K|18|S|26|2|
|3|D|11|L|19|T|27|3|
|4|E|12|M|20|U|28|4|
|5|F|13|N|21|V|29|5|
|6|G|14|O|22|W|30|6|
|7|H|15|P|23|X|31|7|
|填充|=|||||||
|||||||||
|Base32将任意字符串按照字节进行切分,并将每个字节对应的二进制值(不足8比特高位补0)串联起来,按照5比特一组进行切分,并将每组二进制值转换成十进制来对应32个可打印字符中的一个。||||||||
由于数据的二进制传输是按照8比特一组进行(即一个字节),因此Base32按5比特切分的二进制数据必须是40比特的倍数(5和8的最小公倍数)。例如输入单字节字符“%”,它对应的二进制值是“100101”,前面补两个0变成“00100101”(二进制值不足8比特的都要在高位加0直到8比特),从左侧开始按照5比特切分成两组:“00100”和“101”,后一组不足5比特,则在末尾填充0直到5比特,变成“00100”和“10100”,这两组二进制数分别转换成十进制数,通过上述表格即可找到其对应的可打印字符“E”和“U”,但是这里只用到两组共10比特,还差30比特达到40比特,按照5比特一组还需6组,则在末尾填充6个“=”。填充“=”符号的作用是方便一些程序的标准化运行,大多数情况下不添加也无关紧要,而且,在URL中使用时必须去掉“=”符号。
与Base64相比,Base32具有许多优点:
- 适合不区分大小写的文件系统,更利于人类口语交流或记忆。
- 结果可以用作文件名,因为它不包含路径分隔符 “/”等符号。
- 排除了视觉上容易混淆的字符,因此可以准确的人工录入。(例如,RFC4648符号集忽略了数字“1”、“8”和“0”,因为它们可能与字母“I”,“B”和“O”混淆)。
- 排除填充符号“=”的结果可以包含在URL中,而不编码任何字符。
Base32也比Base16有优势:
- Base32比Base16占用的空间更小。(1000比特数据Base32需要200个字符,而Base16则为250个字符)
Base32的缺点:
- Base32比Base64多占用大约20%的空间。因为Base32使用8个ASCII字符去编码原数据中的5个字节数据,而Base64是使用4个ASCII字符去编码原数据中的3个字节数据。
4、Base16——示例61646D696E
它的特点是没有等号并且数字要多于字母
Base16编码的方式:
1.将数据(根据ASCII编码,UTF-8编码等)转成对应的二进制数,不足8比特位高位补0。然后将所有的二进制全部串起来,4个二进制位为一组,转化成对应十进制数。
2.根据十进制数值找到Base16编码表里面对应的字符。Base16是4个比特位表示一个字符,所以原始是1个字节(8个比特位)刚好可以分成两组,也就是说原先如果使用ASCII编码后的一个字符,现在转化成两个字符。数据量是原先的2倍。
|值|编码|值|编码|
|—|—|—|—|
|0|0|8|8|
|1|1|9|9|
|2|2|10|A|
|3|3|11|B|
|4|4|12|C|
|5|5|13|D|
|6|6|14|E|
|7|7|15|F|
|Base16编码是一个标准的十六进制字符串(注意是字符串而不是数值),更易被人类和计算机使用,因为它并不包含任何控制字符,以及Base64和Base32中的“=”符号。||||

5、Base85——示例@:X4hDWe0rkE(G[OdP4CT]N
特点是奇怪的字符比较多,但是很难出现等号

6、Base100——示例👘👛👤👠👥
特点就是一堆Emoji表情
Base100编码/解码工具(又名:Emoji表情符号编码/解码),可将文本内容编码为Emoji表情符号;同时也可以将编码后的Emoji表情符号内容解码为文本。

常用解密网站:
Base64:
Base58:
Base32、16:
Base100:
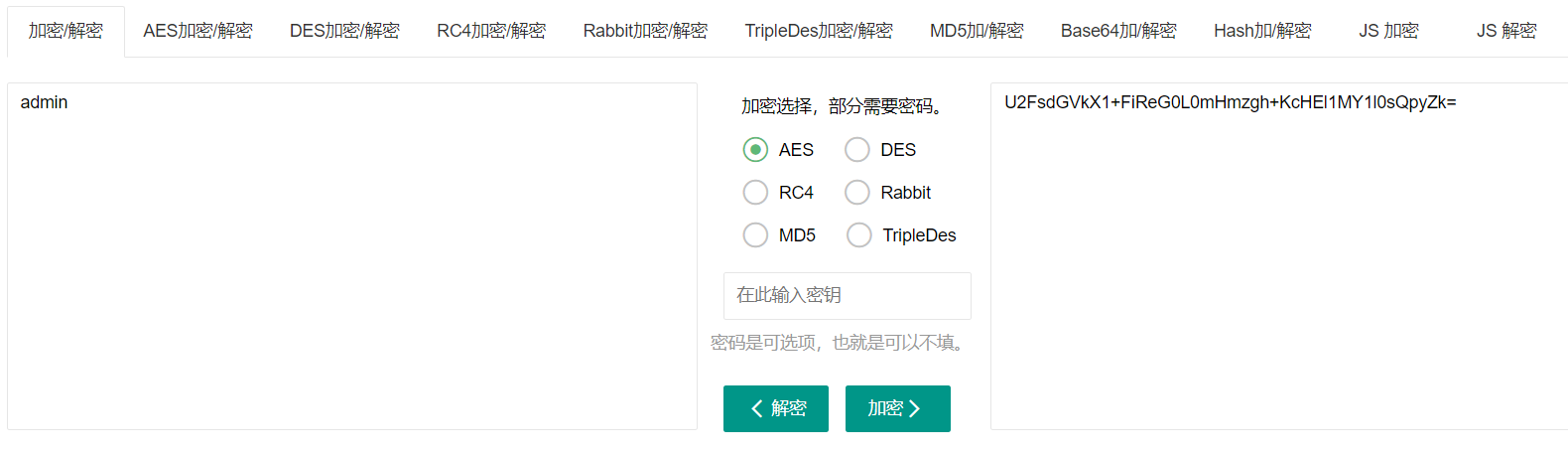
三、AES、DES、RC4、Rabbit、Triple DES(3DES)
这些算法都可以引入密钥,密文特征与Base64类似,明显区别是秘文里+比较多,并且经常出现/
常用解密网站:
https://www.sojson.com/encrypt.html
四、Unicode、HTML实体编码、16进制Unicode
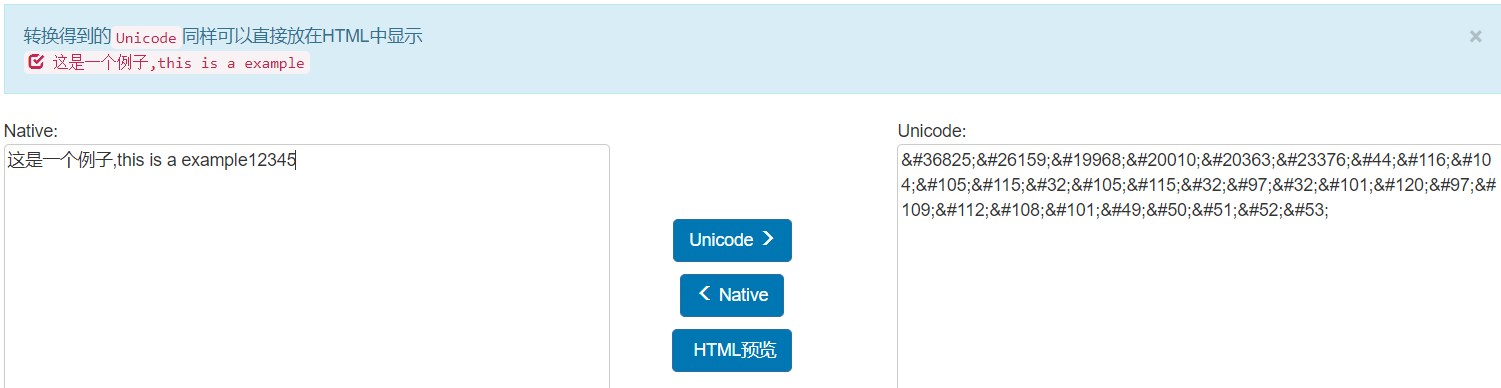
1、Unicode——汉字示例这、字母示例t、数字符号示例5
可以说Unicode与HTML实体编码是一个东西
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
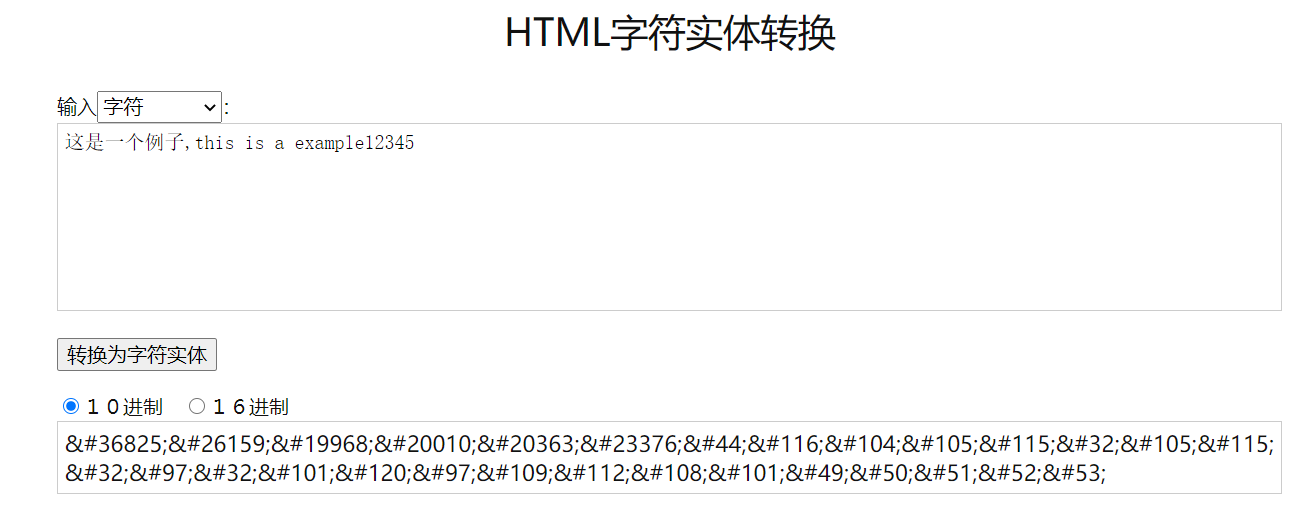
2、HTML实体编码——示例与Unicode相同
字符实体是用一个编号写入HTML代码中来代替一个字符,在使用浏览器访问网页时会将这个编号解析还原为字符以供阅读。
这么做的目的主要有两个:
1、解决HTML代码编写中的一些问题。例如需要在网页上显示小于号(<)和大于号(>),由于它们是HTML的预留标签,可能会被误解析。这时就需要将小于号和大于号写成字符实体: 小于号这样写:< 或 < 大于号这样写:> 或 > 前面的写法称为实体名称,后面的写法则是实体编号。ISO-8859-1字符集(西欧语言)中两百多个字符设定了实体名称,而对于其它所有字符都可以用实体编号来代替。
2、网页编码采用了特定语言的编码,却需要显示来自其它语言的字符。例如,网页编码采用了西欧语言ISO-8859-1,却要在网页中显示中文,这时必须将中文字符以实体形式写入HTML代码中。
2、16进制Unicode——示例\u8fd9\u662f\u4e00
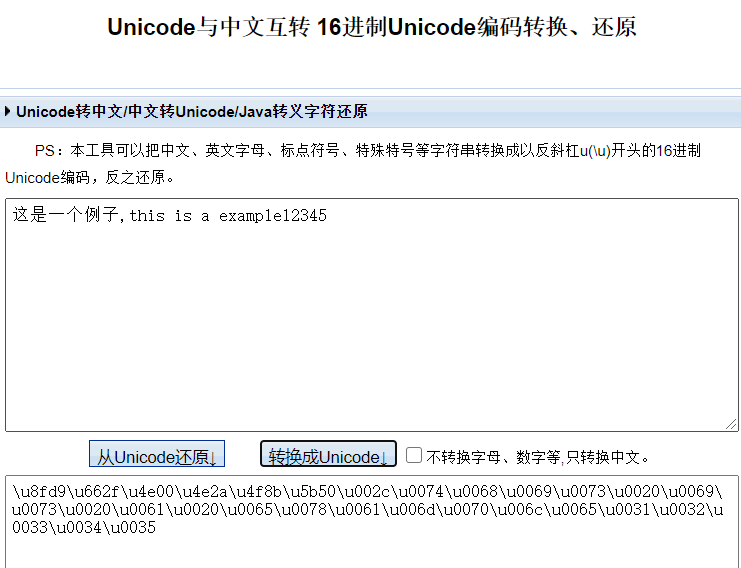
常用解密网站:
- Unicode:www.sojson.com
- 16进制Unicode:www.msxindl.com
- HTML字符实体:www.qqxiuzi.cn
五、Escape编码/加密、Unescape解码/解密、%u编码、%u解码
特征:以%u开头
Escape/Unescape加密解码/编码解码,又叫%u编码,从以往经验看编码字符串出现有"u”,它是unicode编码,那么Escape编码采用是那一种unicode实现形式呢。其实是UTF-16BE模式。这样一来问题非常简单了。 Escape编码/加密,就是字符对应UTF-16 16进制表示方式前面加%u。Unescape解码/解密,就是去掉”%u"后,将16进制字符还原后,由utf-16转码到自己目标字符。如:字符“中”,UTF-16BE是:“6d93”,因此Escape是“%u6d93”,反之也一样!因为目前%字符,常用作URL编码,所以%u这样编码已经逐渐被废弃了!
基本类型只对汉字进行编码,复杂类型是所有字符均可
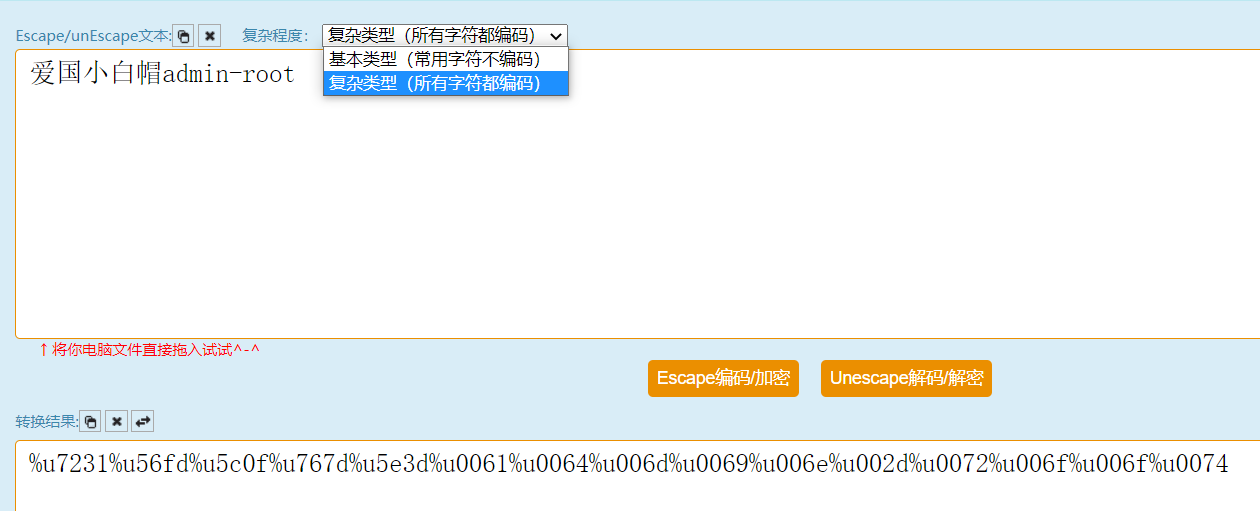
常用解密网站:
六、URL、Hex编码
这两种加密的密文是一样的,不同的是当你用url编码网站时是不会把http进行编码的,而Hex编码则全部转化了
encodeURIComponent() 函数 与 encodeURI() 函数的区别 请注意 encodeURIComponent() 函数 与 encodeURI() 函数的区别之处,前者假定它的参数是 URI 的一部分(比如协议、主机名、路径或查询字符串)。因此 encodeURIComponent() 函数将转义用于分隔 URI 各个部分的标点符号。
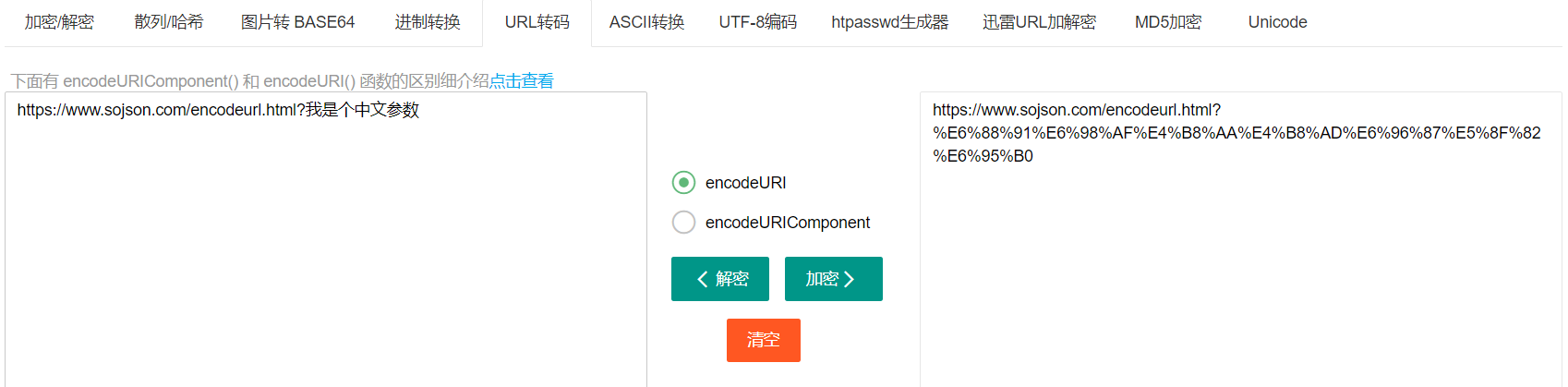
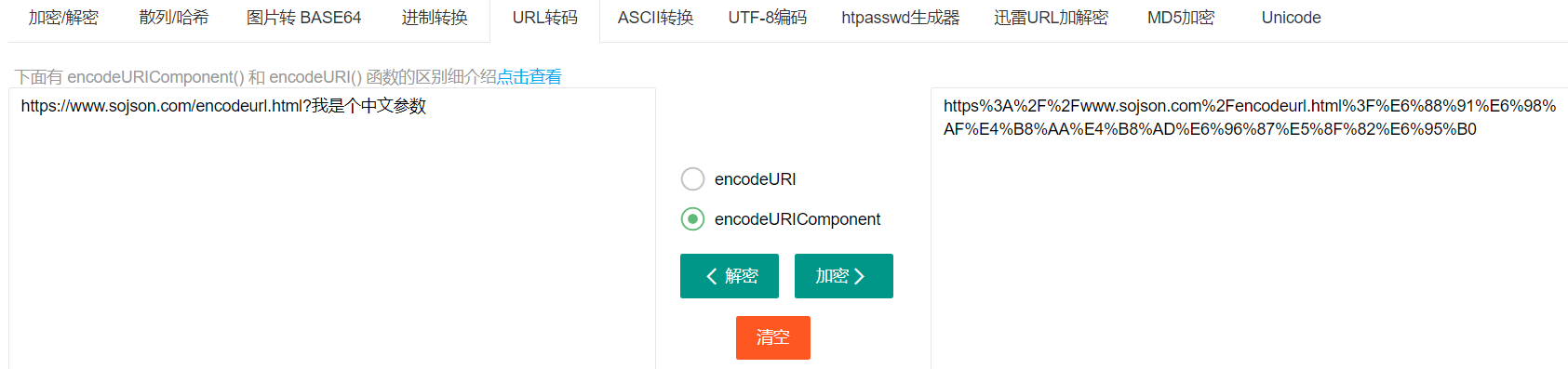
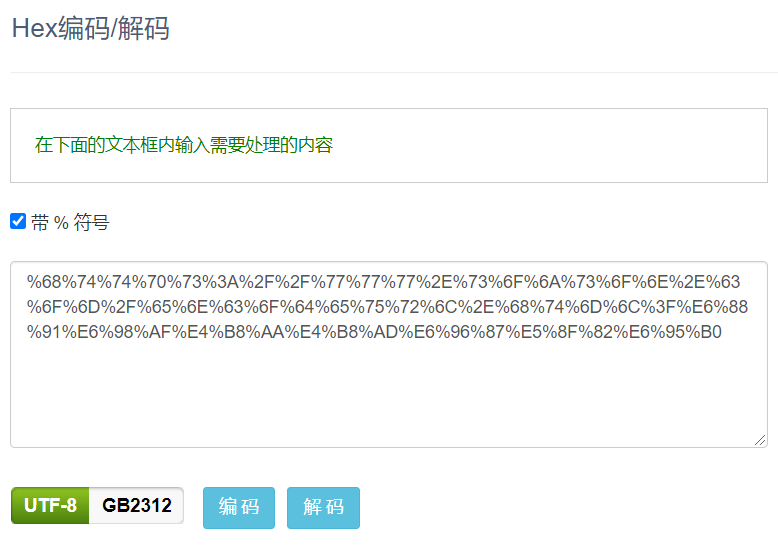
常用解密网站:
七、凯撒密码、维吉尼亚密码、栅栏密码基础型、栅栏密码W型
这几类密码原理都是移位调换加密,破解难度低
1、凯撒密码——示例iodj{khoor_zrug_123}
只对字母进行加密,常用于CTF比赛中
凯撒密码最早由古罗马军事统帅盖乌斯·尤利乌斯·凯撒在军队中用来传递加密信息,故称凯撒密码。此为一种位移加密手段,只对26个(大小写)字母进行位移加密,规则相当简单,容易被破解。下面是明文字母表移回3位的对比: 明文字母表 X Y Z A B C D E F G H I J K L M N O P Q R S T U V W 密文字母表 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 然后A变成D,B变成E,Z变成C。 字母最多可移动25位(按字母表)。通常为向后移动,如果您想向前移动1位,则相当于向后移动25位,位移选择为25位。
2、维吉尼亚密码——示例fmcg{iglmq_wptd_123}
可以说是凯撒密码的加强版,引入了密钥
维吉尼亚密码,它将凯撒密码的所有26种排列放到一个表中,形成26行26列的加密字母表。此外,维吉尼亚密码必须有一个由字母组成的密钥,至少有一个字母,最多与明文字母有相同数量的字母。 在凯撒密码中,每个字母都会进行一定偏移值转换,例如,当偏移值是3时,则B被转换为E,C转换成F…。在维吉尼亚密码加密中,则是由具有不同偏移的凯撒密码构成的。 要生成密码,需要使用表格方法,此表(如图所示)包含26行字母表,每一行从上一行到左行被一位偏移。加密时使用哪一行字母表是基于密钥的,在加密过程中密钥会不断变化。 例如,假设明文为: BTTACKATDAFG 选择一个关键字并重复它以获得密钥,例如,当关键字是LIMN时,键是: LIMNLIMNLIMN 在明文中的第一个字母B,对应于密钥中的第一个字母L,使用加密字母表中的L行字母进行加密,得到第一个字母的密文M。同样,第二个明文字母是T,它用表中的I行加密,得到第二个密文B。通过类比,我们可以得到: 明文:BTTACKATDAFG 键:LIMNLIMNLIMN 密文:MBFNNSMGOIRT 解密的过程是加密的逆过程。例如,密钥的第一个字母对应的L行字母表,发现密文的第一个字母M位于B列,因此明文的第一个字母是B。密钥的第二个字母对应于I行字母表,而密文的第二个字母B位于该行的T列中,因此明文的第二个字母是T。等等,你可以得到明文。
3、栅栏密码基础型
栅栏密码是按一定规则将明文内容互相调换了位置
栅栏密码(Rail fence Cipher)基础型加密方式,是一种简单的移动字符位置的加密方法,首先把加密的明文分成N个一组,然后把每组的第1、第2、第M个字符连起来,形成无规律的密文字符串。
例如字符串“123456789abc”,首先将字符串分成3组,如下排列: 1234 5678 9abc 依次取每一组字符,组成加密后密文:“15926a37b48c”。
4、栅栏密码W型
栅栏密码W型加密算法: 栅栏密码(Rail fence Cipher),扩展变种W型,采用先把明文类似"W"形状进行排列,然后再按栏目顺序1-N,取每一栏的所有字符值,组成加密后密文。 比如字符串“123456789”,采用栏目数为3的时,明文将采用如下排列: 1—5—9 -2-4-6-8- –3—-7– 取每一栏所有字符串,组成加密后密文:“159246837”。 W型栅栏密码加密方式,比传统型栅栏密码加密方法,算法略有增强,但目前已只能用于学习算法验证。
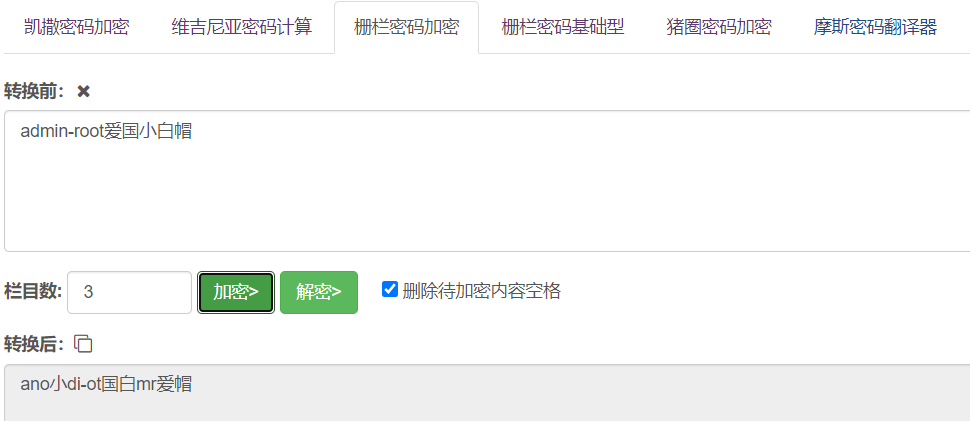
常用解密网站:
- 凯撒密码:www.qqxiuzi.cn
- 维吉尼亚密码:www.metools.info
- 栅栏密码基础性:www.metools.info
- 栅栏密码W型:www.metools.info
八、文本隐藏加密、零宽隐写
1、文本隐藏加密
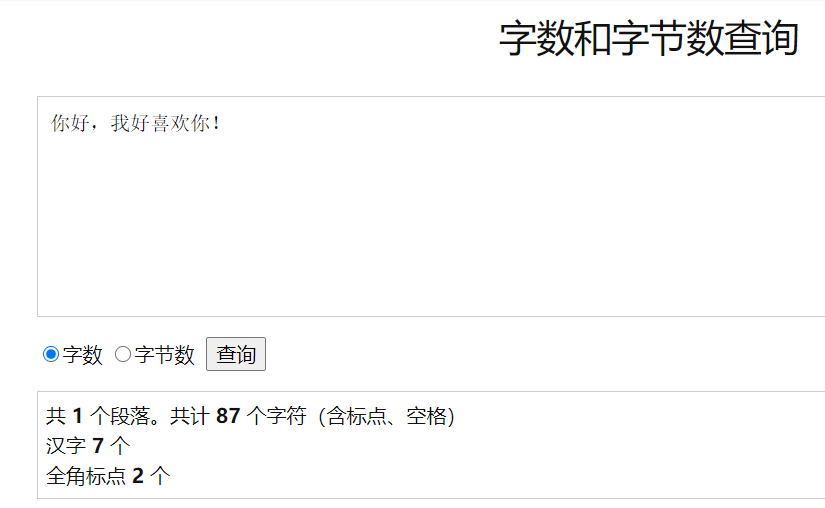
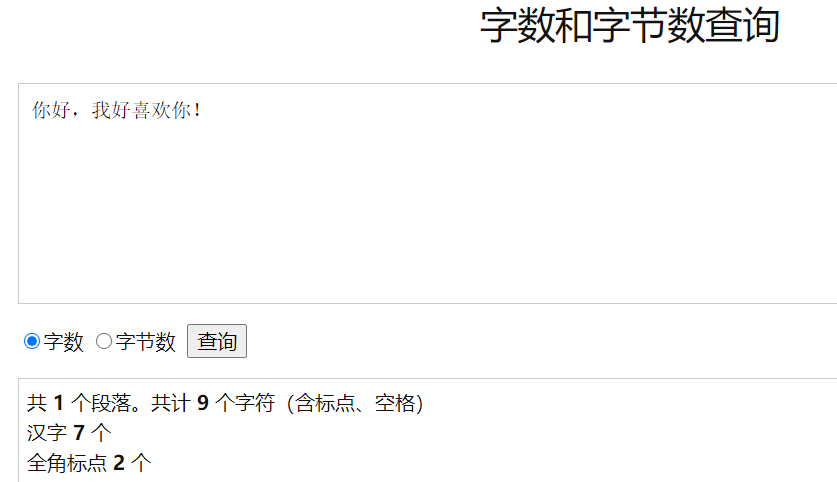
特征:加密过的密文会比原文的字节数多,当你按删除键的时候会发现某一处要按好多下才能把前面的字删掉
原理**:它的原理是在密文中加入了不可见字符组成的编码,例如上述看似九个字符的一句话,通过字数查询可知它实际上有87个字符,多出的字符是由零宽空格实现的编码,因为零宽空格不占据空间,所以看不出它的存在。
使用:在进行文本隐藏加密时,将需要隐藏的文字写在括号中,就像这样“你好(有才华),我好喜欢你(画的画)!”,然后加密即可隐藏括号内的文字。同时可以设定一个密码,这样只有知道密码的人才能解密隐藏的文字。密码可以是数字、字母和下划线,最多九位。

这是加密后的字节数
这是本来的字节数
2、零宽隐写
特征:解密后明文与密文会分开显示,密文一般隐藏在第一个字后面,不信你试试,保证你十下之内删不完
与上面文本隐藏加密的原理一样,但过程不一样

(https://www.nerubian.cn/upload/20201107133427168.png)
这里加密过的密文在文本隐藏加密中解不出来

常用解密网站:
文本隐藏加密:www.qqxiuzi.cn
零宽隐写:yuanfux.github.io
九、特殊暗号类加密
这类加密都是特征性比较强的,易辨别
1、猪圈密码
特点:只能对字母加解密并且符号无法复制,粘贴后会直接显示明文
猪圈密码(亦称朱高密码、共济会暗号、共济会密码或共济会员密码),是一种以格子为基础的简单替代式密码,曾经是美国内战时盟军使用的密码,目前仅在密码教学、各种竞赛中使用。
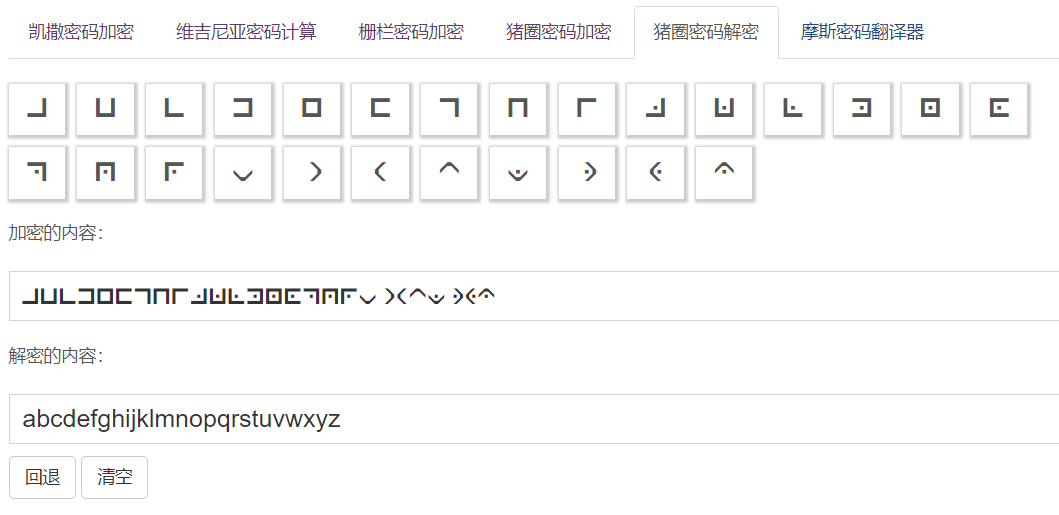
常用解密网站:
http://www.metools.info/code/c90.html
2、与佛论禅
特点:就是你看不懂的佛语
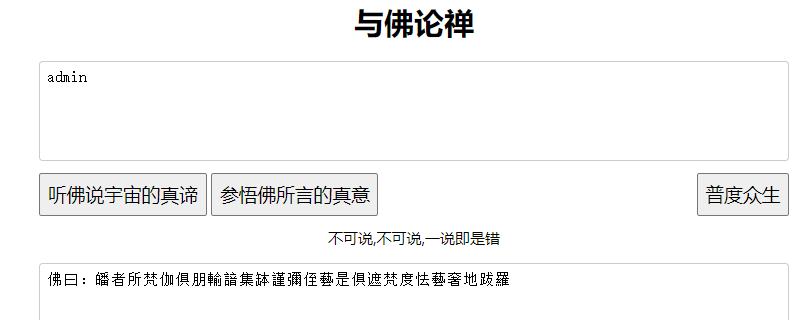
常用解密网站:
http://www.keyfc.net/bbs/tools/tudoucode.aspx
3、百家姓暗号
特征:不要多说当你看到一串百家姓的时候多半就是这个暗号了

当他解密的的时候前面会多一串固定字符

常用解密网站:
https://www.ahz0.com/bjx.html https://www.w168.net/anhao.html https://api.dujin.org/baijiaxing/ https://www.ddosi.com/ah.html
4、卡尔达诺栅格码
特征:把明文伪装成垃圾邮件,看着这么多内容,其实我只是加密了admin

常用解密网站:
5、莫尔斯电码
特征:密文由不规律的.、/、-组成
摩尔斯电码(Morse alphabet)(又译为摩斯电码)是一种时通时断的信号代码,这种信号代码通过不同的排列顺序来表达不同的英文字母、数字和标点符号等。 由美国人摩尔斯(Samuel Finley Breese Morse)于1837年发明,为摩尔斯电报机的发明(1835年)提供了条件。 摩尔密码加密的字符只有字符,数字,标点,不区分大小写,支持中文汉字 中文摩斯加密解密:本工具摩尔密码加密是互联网上唯一一个可以对中文进行摩斯编码的工具。 莫尔斯电码加密列表 | Morse Code List 一、26个字母的莫尔斯电码加密
|字符|电码符号|字符|电码符号|字符|电码符号|字符|电码符号|
|—|—|—|—|—|—|—|—|
|A|.━|B|━ ...|C|━ .━ .|D|━ ..|
|E|.|F|..━ .|G|━ ━ .|H|....|
|I|..|J|.━ ━ ━|K|━ .━|L|.━ ..|
|M|━ ━|N|━ .|O|━ ━ ━|P|.━ ━ .|
|Q|━ ━ .━|R|.━ .|S|...|T|━|
|U|..━|V|...━|W|.━ ━|X|━ ..━|
|Y|━ .━ ━|Z|━ ━ ..|||||
二、数字的莫尔斯电码加密
|字符|电码符号|字符|电码符号|字符|电码符号|字符|电码符号|
|—|—|—|—|—|—|—|—|
|0|━ ━ ━ ━ ━|1|.━ ━ ━ ━|2|..━ ━ ━|3|...━ ━|
|4|....━|5|.....|6|━ ....|7|━ ━ ...|
|8|━ ━ ━ ..|9|━ ━ ━ ━ .|||||
三、标点符号的莫尔斯电码加密
|字符|电码符号|字符|电码符号|字符|电码符号|字符|电码符号|
|—|—|—|—|—|—|—|—|
|.|.━ .━ .━|:|━ ━ ━ ...|,|━ ━ ..━ ━|;|━ .━ .━ .|
|?|..━ ━ ..|=|━ ...━|’|.━ ━ ━ ━ .|/|━ ..━ .|
|!|━ .━ .━ ━|━|━ ....━|_|..━ ━ .━|“|.━ ..━ .|
|(|━ .━ ━ .|)|━ .━ ━ .━|$|...━ ..━|&|. ...|
|@|.━ ━ .━ .|||||||
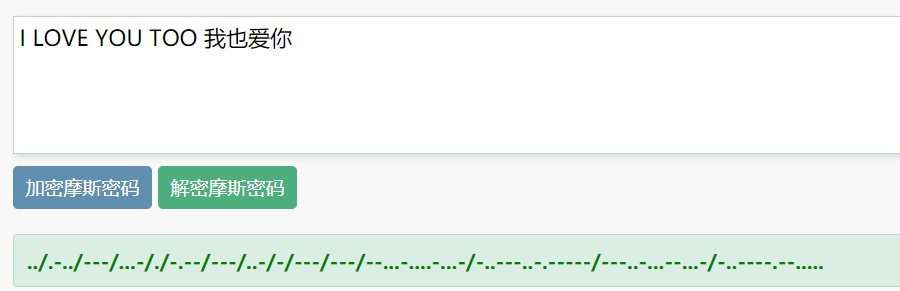
常用解密网站:
https://www.atool99.com/morse.php
6、Quoted-Printable
这种编码常用与邮件处理,只能对汉字进行编码,特征是=加两个大写字母或数字组合
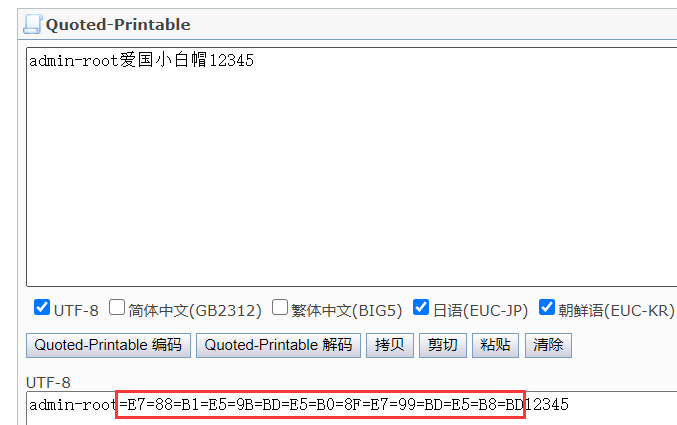
常用解密网站:
http://www.mxcz.net/tools/QuotedPrintable.aspx
7、ROT13
特征:它与凯撒密码差不多都是字母替换,你看到一句特别奇怪的语句可能就是它编码的
ROT13(回转13位,Template:lang,有时中间加了个减号称作ROT-13)是一种简易的置换暗码。它是一种在网路论坛用作隐藏八卦(spoiler)、妙句、谜题解答以及某些脏话的工具,目的是逃过版主或管理员的匆匆一瞥。 ROT13被描述成「杂志字谜上下颠倒解答的Usenet对等体」(Usenet equivalent of a magazine printing the answer to a quiz upside down.)Template:cite web ROT13也是过去在古罗马开发的凯撒加密的一种变体。
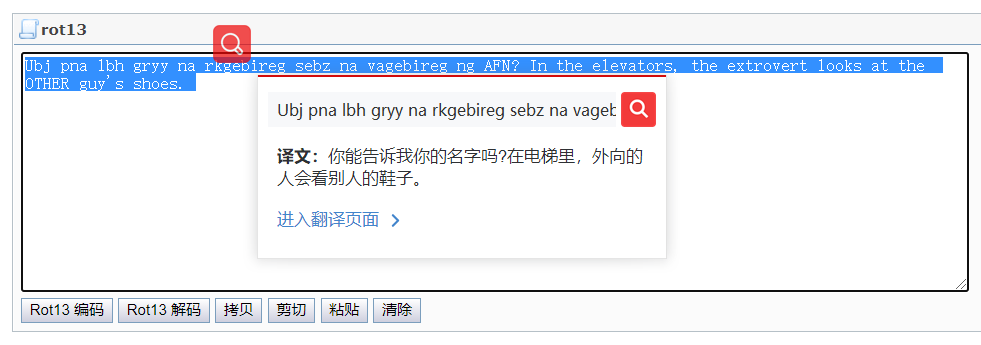
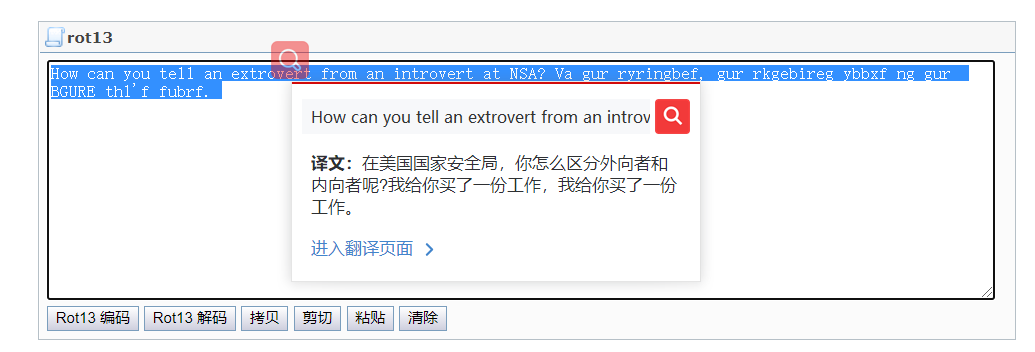
常用解密网站:
http://www.mxcz.net/tools/rot13.aspx
8、文本加密为汉字
特征:将明文加密成各种繁体字后面带俩等号

它不仅可以加密成汉字,还可以加密成以下几种类型

比如这样:

这样:
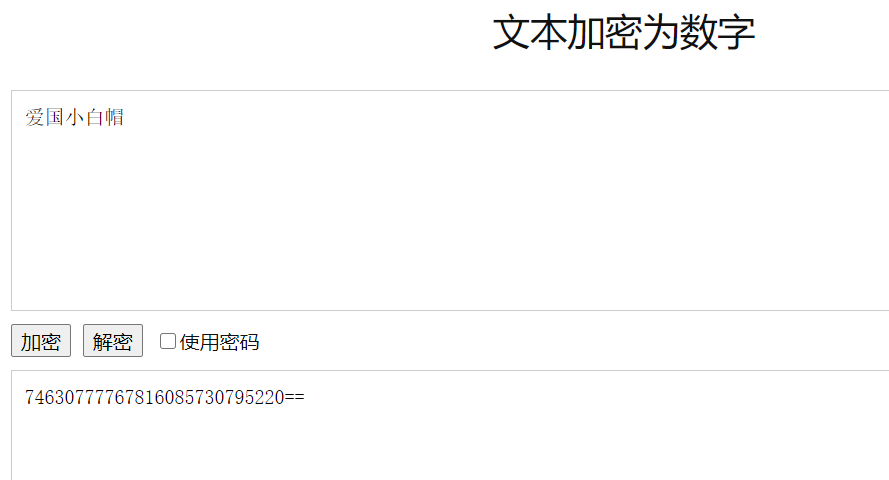
常用解密网站:
https://www.qqxiuzi.cn/bianma/wenbenjiami.php
9、brainfuck密文解密网站
https://tool.bugku.com/brainfuck/?wafcloud=1
十、js专用加密
1、颜文字js加密
特征:一堆颜文字构成的js代码,在F12中可直接解密执行
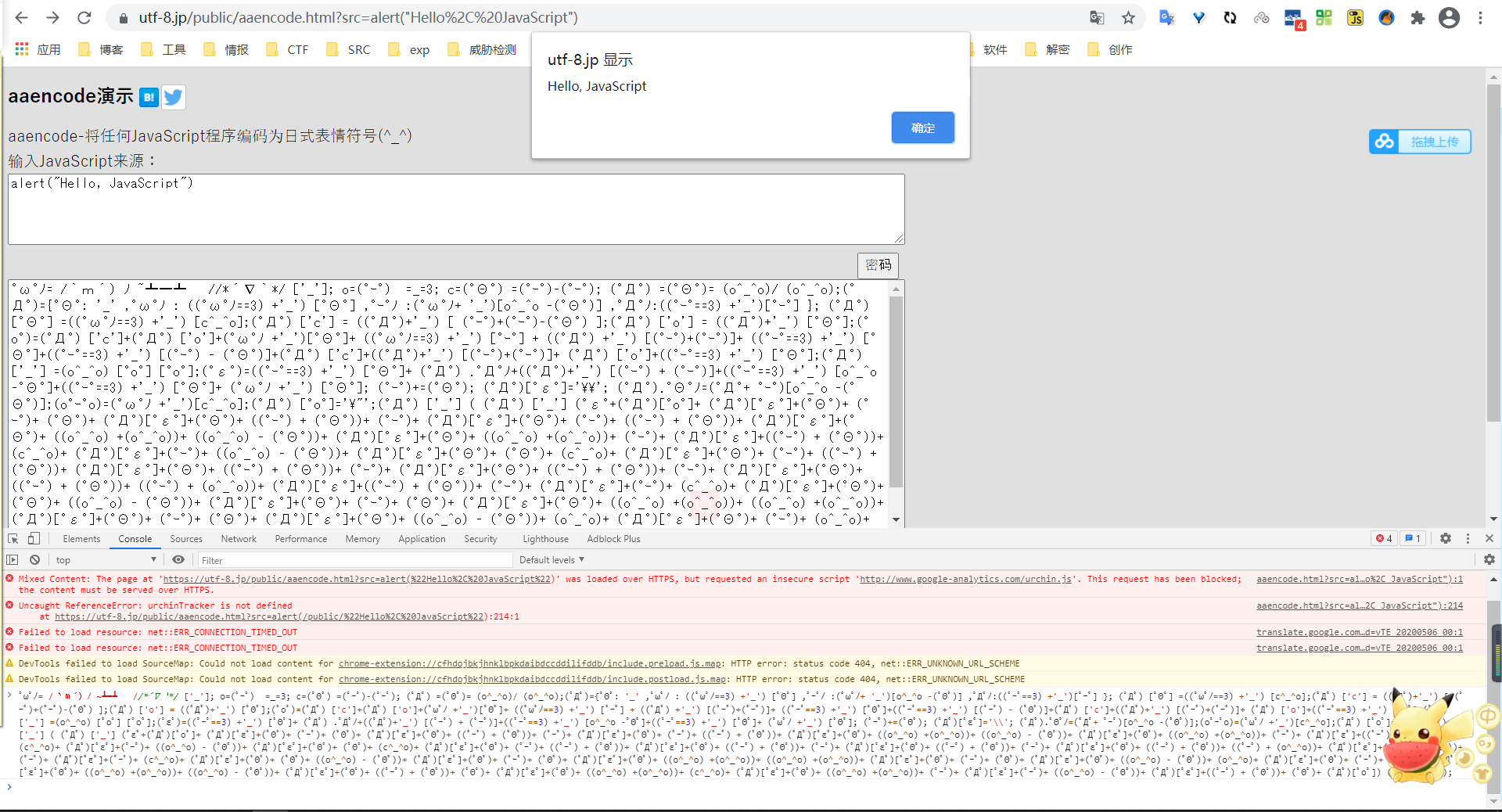
常用解密网站:
https://utf-8.jp/public/aaencode.html
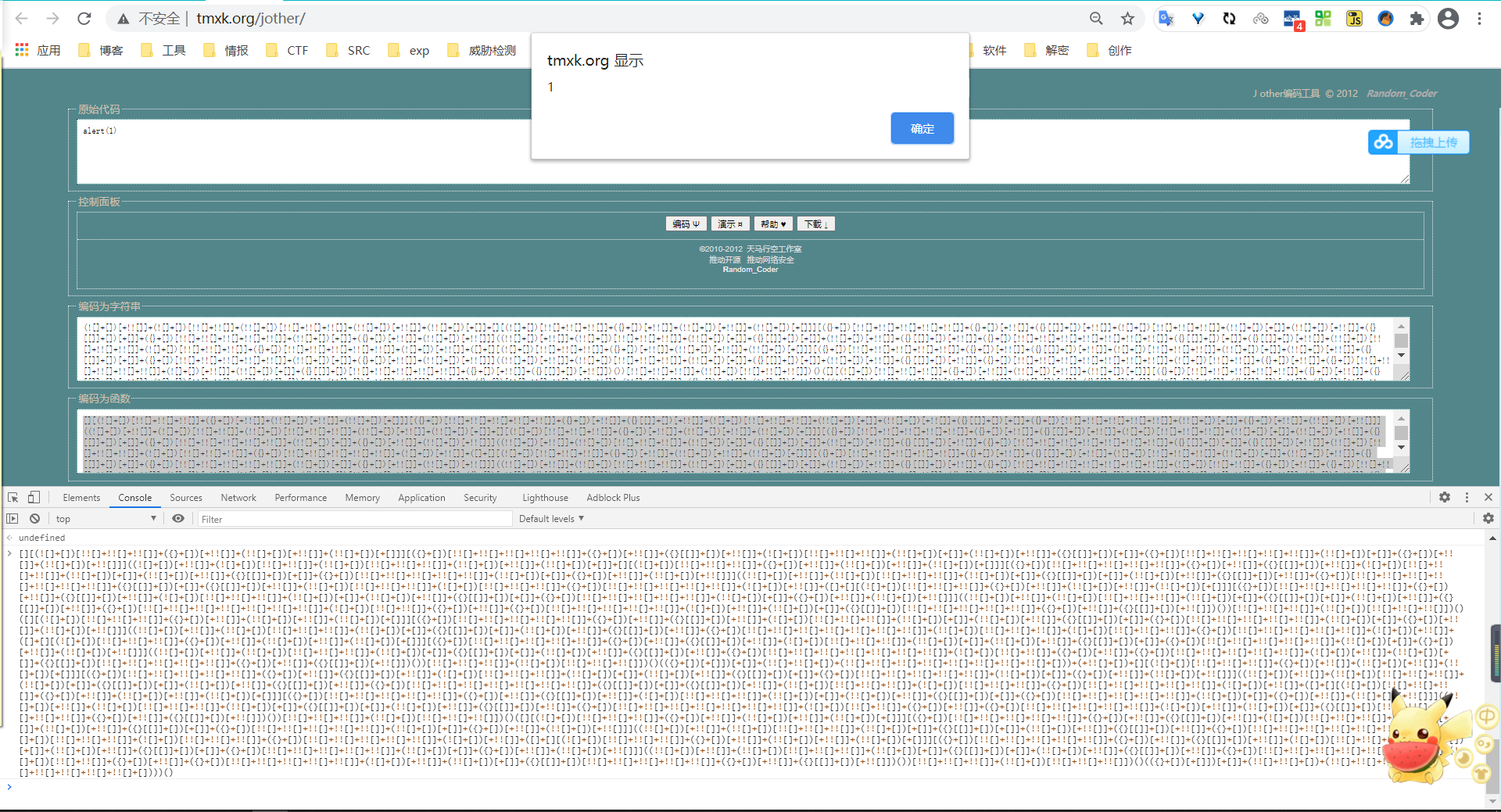
2、jother编码
特征:只用! + ( ) [ ] { }这八个字符就能完成对任意字符串的编码。也可在F12中解密执行
常用解密网站:
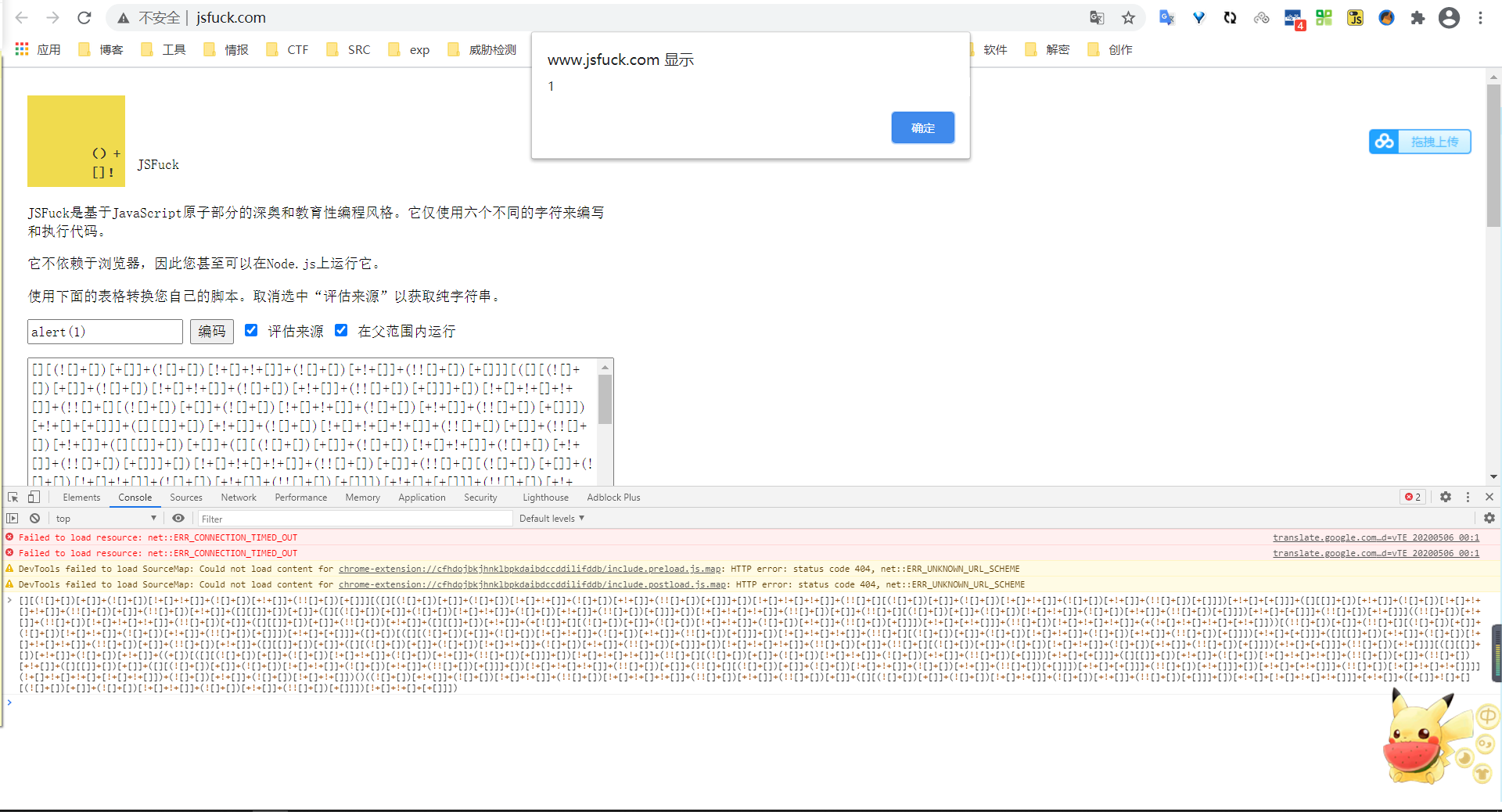
3、JSFuck编码
特征:与jother很像,只是少了{ }
常用解密网站:
- 使用方法:将密文复制进中间的文本框中,点击右下角的Run this
- 需要将所有的其他字符去掉,否则会执行失败
- 此语言本质上是一种代码混淆,所以一般是将所有密文一起放入
原文链接:https://blog.csdn.net/weixin_45728976/article/details/109219997
